How we built Osmium for scale
Why we wrote our own actor framework in Rust, and how it works

TL;DR - We built our own actor framework in Rust from scratch. Here’s why we did that, what the benefits are over other solutions, and some details about how it works.
The way many fast-moving startups solve scaling nowadays is by throwing money at cloud providers, but we wanted to do things differently. First of all, we are self funded, don’t have (and don’t want) VC funds, so we have to be cost-conscious. Second of all, we strongly dislike being dependent on third-party providers. We rent physical servers, use a third-party payment provider, and a CDN for serving the website and static files. We selfhost everything else, including Git, CI runners, VPN, databases, observability, and everything else needed for running a chat app in production. Running stuff ourselves feels great - if it breaks, we can fix it, instead of waiting for someone else to.
Designing a chat app
So, how does one design a chat platform? Reducing a chat app to its very basics involves roughly two things - loading previously sent messages and sending+receiving new messages. The first part is relatively simple - you have some database with a table of messages with some indexes, when you load existing messages it does a db query and gives it back to you, done. Sending+receiving messages gets a little more interesting - all users that are in a channel should receive a notification that there’s a new message in a channel they follow. Going from first principles - the way to solve this is to have some sort of a pub/sub system, where users that are online subscribe to channels they follow, and sending a message publishes a message to this system. One way to do this would be using Redis Pub/Sub - a relatively easy solution, this is for example what Stoat does. This means that if a user sends a message, the message gets serialized, sent to Redis and distributed across other nodes where users are connected, deserialized and sent to users over some kind of client socket. But what if there was a different, better way? What if, when two users are connected to the same machine, you could skip the network trips entirely? Optimizing for performance at this level is surprisingly important, and so we looked at a different kind of infrastructure modelling.
Actors
There is a concept in computer science called the actor model. The basics are these - you have some state wrapped in an actor and you can only talk to actors by sending them messages and them sending you responses back. By imposing this kind of structure on your code, you actually get a really nice benefit - if your messages are serializable into bytes, the actors talking to each other don’t need to be on the same machine, and suddenly you have a stateful app AND you can scale horizontally at the same time. In a “standard” REST API in modern apps the APIs are stateless and all state is stored in databases, which the APIs then talk to. This usually means that for every request you have to do a bunch of round trips to the network, to some cache for rate limits, to some database for reading/writing data, etc. With the actor model, you can store a lot of data directly in memory, and databases become significantly less important.
A popular language implementing the actor model is Elixir - this is also what Discord runs on. It gives you some awesome features out of the box, like moving actors across nodes and automatic node discovery. It does, however, also have its drawbacks - relatively old-school syntax, limited type checking and the fact that it is garbage collected and runs on Erlang VM. These are significant drawbacks partially because we aren’t familiar with Elixir syntax, and partially because performance is critical and Elixir can slow you down. Discord has been known to write native modules for Elixir in Rust to make up for the performance issues. Rust is a language that we are familiar with, and was therefore our choice to go with.
Osmium structure
We ended up writing Nucleus, our own Rust crate implementing the actor model from scratch, given our specific requirements. It allows us to create Nucleus nodes that listen, discover, and talk to each other. We can define our own actor types, message handlers, and then Nucleus handles everything in between. As a consequence of it not running in a VM like Elixir/Erlang, it requires us to define explicitly how the messages and actors are serialized and deserialized so that they can be moved between nodes. For this we chose to use Protobuf, as it has good ecosystem support and offers nice backwards compatibility guarantees.
Discovery
When I have actor User-A and I send a message to Channel-B, the actor User-A first needs to find where Channel-B is located, and whether it exists at all. Nucleus keeps track of all named actors on its node, and nothing else. By default, to find Channel-B, Nucleus will send a discovery message to all nodes in the cluster. This serves well with low traffic, but scales quadratically, aka not well. Specifically, each node in the cluster has to handle each discovery message, even if in most cases Channel-B is not located on that node. To solve this, we use a consistent hashing hash ring. We keep track of all nodes that are known to handle user actors, and use the ring to determine which of those nodes an actor belongs to. Nucleus is then only required to ask that node, and won’t send meaningless traffic to irrelevant nodes. A hash ring is efficient when it comes to adding new nodes into the ring - it will load balance the existing actors evenly, and minimizes the number of actors that need to move between nodes. For this logic we use a slightly modified version of this crate.
Pubsub
Nucleus is forced to implement pubsub in an efficient way. When an actor publishes a message, the subscribers should not each receive a raw copy of the message. Instead, they receive an atomically counted reference, which makes fanning out messages significantly more efficient. This also happens when the subscriber and the publisher are not on the same node - the node of the publisher sends a single copy of the message to the node of the subscriber, and all subscribers on that node receive a reference to the same message. Given that there will be many messages received by many users, this kind of efficiency matters. In fact, this is one of the most common messages in Osmium by far - if I send a single message into a channel, it will then be received by N subscribers, where N can go into the thousands.
Actor model structure
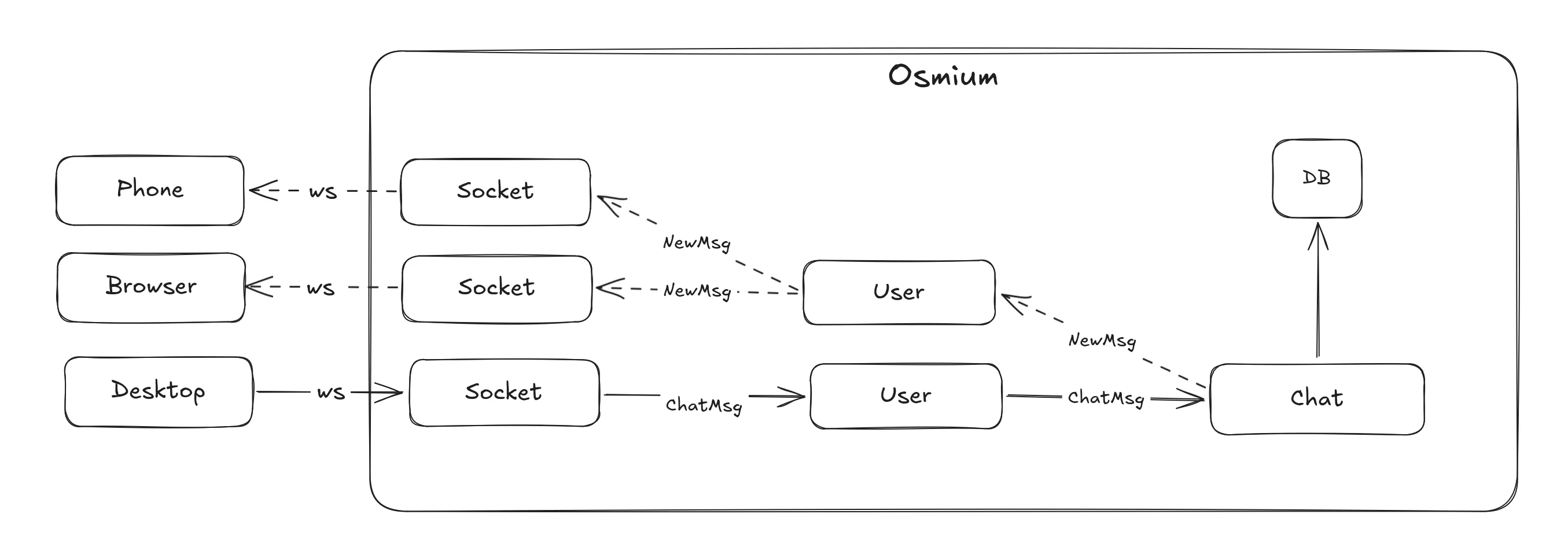
For the core flow, Osmium has three actor types - socket, user and chat. Socket is the actor that holds the actual (web)socket connection as its state, and exists mostly to forward messages to and from the user. User is the actor that holds all the user state - what user it is, what channels the user is subscribed to, which messages are unread, etc. Chat is then an actor that holds the actual chat data. It holds information like name, permissions, members, and is what actually writes received messages to the database. The chat acts also as a publisher that the users subscribe to to receive new messages. Sockets then subscribe to the user actor they belong to, and proxy the updates to the end user over the WebSocket. Why not skip the Socket actor entirely? The answer is reliablity - if a node running socket actors gets overloaded, for example due to a DDoS attack, all connected users can transparently connect to a different socket node and resume with no issues, since all stateful actors remain isolated.
Nucleus benchmarks
We have invested a lot of time into optimizing Nucleus and making sure the performance is what it needs to be. I spent several evenings running benchmarks, looking at perf flamegraphs, optimizing allocations, and trying out different combinations. Here are the results for a simple fire-and-forget throughput benchmark using 8 sender threads between remote nodes:
| Language | Messages per second | Speedup over Elixir |
|---|---|---|
| Rust (Nucleus) | 1.270 Mmsg/s | 1.7x |
| Rust (Nucleus, with metrics) | 1.134 Mmsg/s | 1.5x |
| Elixir (GenServer) | 744 Kmsg/s | - |
| Rust (Nucleus, experimental allocator)* | 1.475 Mmsg/s | 2.0x |
Nucleus has a 1.7x higher throughput than Elixir in this benchmark. Of course, as with all synthetic benchmarks, take it with a grain of salt, but the results are promising. Here is the result for a fire-and-forget benchmark between actors on the same node, also using 8 sender threads:
| Language | Messages per second | Speedup over Elixir |
|---|---|---|
| Rust (Nucleus) | 4.216 Mmsg/s | 1.66x |
| Rust (Nucleus, with metrics) | 2.453 Mmsg/s | 0.96x |
| Elixir (GenServer) | 2.530 Mmsg/s | - |
| Rust (Nucleus, experimental allocator)* | 5.371 Mmsg/s | 2.12x |
* Experimental allocator is a custom written memory allocator using a linked list of ring buffers for a subset of frequent allocations that Nucleus does, but is not ready for production
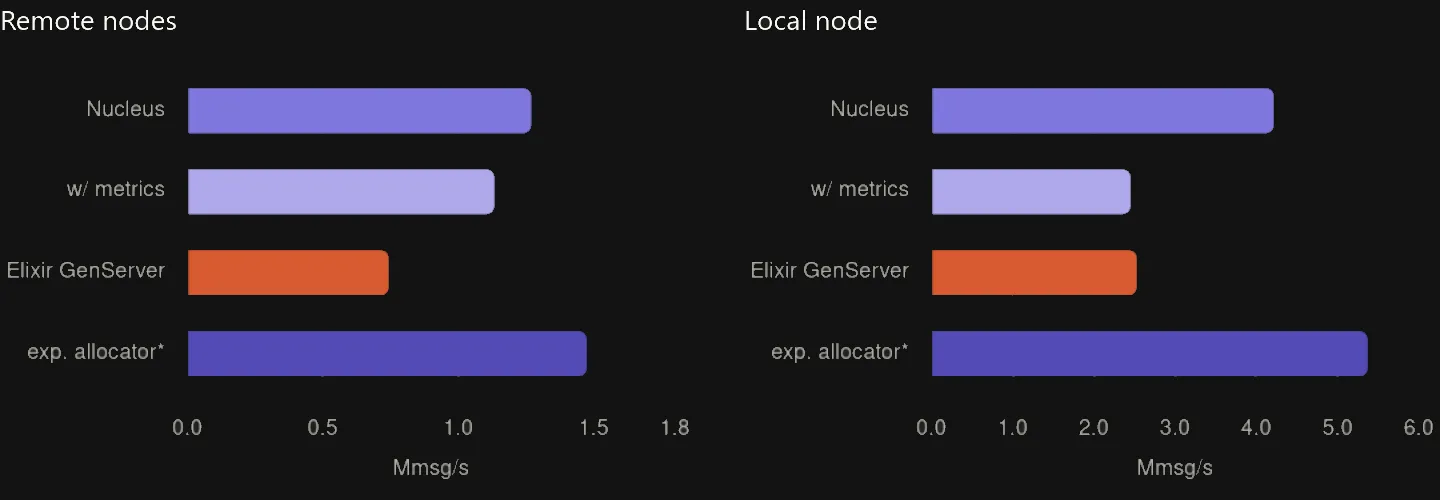
On a local-node benchmark, Nucleus is also approximately 1.7x faster than Elixir. It is also important to note that, by default, Nucleus collects metrics about message handling times for observability, which runs on every message sent between actors. Elixir does not do this at all, but it seemed important to include it in the benchmark, given that this is what Osmium collects in production. These benchmarks were run on an Intel i7-10875H processor. Sources for these benchmarks can be found here and here.
Multi region data storage
If you and your friend are talking to each other directly on Osmium, and both of you are located in Europe, why should your message ever round-trip across continents? This is the reality of many, many apps today - companies host a single database in us-east1 and all your messages are stored there. This is not only bad for privacy and regulations, it’s also bad for latency. We are engineering Osmium in a way where your data will never leave your region, but is handled transparently, so your experience is unaffected. This however is not quite finished yet, and we will write a standalone blog post talking about it when the time comes.
Wrap up
We like building things from the ground up ourselves - it feels good to own such a large part of the stack and we are proud of what we built so far. We are also happy to be able to open-source Nucleus, the most basic building block that Osmium is built on. I hope you enjoyed reading this post.
Thank you for reading and I’ll see you on Osmium!